Databases
This path is all about connecting to Oracle databases like TEMPO and Delta.
Sick dogs
A string of dog deaths has left public health officials scratching their heads. Are cats finally getting their revenge or is there some other funny business at play?
After a few days of chasing down dead-ends, you find a fax waiting for you in your office. The letterhead shows the logo for the Wisconsin DNR. That’s odd. The last time you heard from them was during the great chameleon outbreak of 1992.
The letter contains the following warning:

Prepare yourselves!
The deadly Caninus-morbidium (CM) is believed to be headed your way. We’ve found that it likes warm water and low oxygen, but it really dislikes fish and fast moving water.
According to our measurements we’ve seen them living in temperatures greater than 23 C, but less than 27 C. The dissolved oxygen range has been greater than 4, but less than 6.
Which water bodies in MN would be hospitable to this bacteria?
TEMPO & Delta: Oracle databases
To get started you need to tell your computer where Delta is.
- Open the Control Panel > Administrative Tools > Data Sources (ODBC)
- Click the [Add…] button.
- Driver Name: Oracle in OraClient11g_home2
- Data Source Name: deltaw
- TNS Service Name: deltaw.pca.state.mn.us
You can leave the rest blank. Click the [Test Connection] button.
Enter the top secret User Name: t********* and Password: d***_**.
If you need a user name and password contact the Data Desk at DataDesk.MPCA@state.mn.us.
Once you get a Connection successful! message. You’re all set. Close out and return to RStudio.
Facility locations
Let’s find the location of some facilities.
You can view the available database connections in R using the function odbcDataSources().
library(dplyr)
library(RODBC)
odbcDataSources()## dBASE Files
## "Microsoft Access dBASE Driver (*.dbf, *.ndx, *.mdx)"
## Excel Files
## "Microsoft Excel Driver (*.xls, *.xlsx, *.xlsm, *.xlsb)"
## MS Access Database
## "Microsoft Access Driver (*.mdb, *.accdb)"
## LakesXMLDataSource
## "CR ODBC XML Driver 4.20"
## PostgreSQL35W
## "PostgreSQL Unicode(x64)"
## onbase
## "Oracle in OraClient11g_home1"
## onbaset
## "Oracle in OraClient11g_home1"
## onbased
## "Oracle in OraClient11g_home1"
## deltaw
## "Oracle in OraClient11g_home1"To connect to deltaw use the function odbcConnect().
library(readr)
# Load credentials
credentials <- read_csv("X:/Agency_Files/Outcomes/Risk_Eval_Air_Mod/_Air_Risk_Evaluation/R/R_Camp/Student Folder/credentials.csv")
user <- credentials$delta_user
password <- credentials$delta_pwd
# Or use your own
#user <- "ta*******"
#password <- "da**_*******"
# Connect to Delta
deltaw <- odbcConnect("deltaw",
uid = user,
pwd = password,
believeNRows = FALSE)
# View all schemas in deltaw
sqlTables(deltaw)$TABLE_SCHEM %>% unique() %>% sort()## [1] "ADB" "ADM_DELTA" "APP_EXTERNAL"
## [4] "APP_INTERNAL" "AQ_DELTA" "ASSESS"
## [7] "CGI_RO" "CMP_DATA" "CMP_WEB"
## [10] "CNELSON1" "CORE_SDW" "CORE_WU"
## [13] "CORE_WU_LINK_USER" "COREUSER" "CSW"
## [16] "CTOP_DELTA" "CWU" "DB_COMMENTS"
## [19] "DOCTRACK" "ELM" "ENF_DB"
## [22] "ENV_STDS" "ENV_STDS_LINK_USER" "EQUIS"
## [25] "EQUIS_TEST" "EQUIS_USER" "EQUISDW"
## [28] "EQUISDW2" "EQUISFE" "EQUISPU"
## [31] "EQUISRO" "ETRACK" "FILE_MGT"
## [34] "GRANTS_DATA" "HERE_FLOW" "HW_DELTA"
## [37] "INCIDENT" "ISW" "MIG_AQ_POST_R1"
## [40] "MIG_AQ_POST_R2_CE" "MIG_CNVD" "MIG_DELTA"
## [43] "MIG_DELTA_R2" "MIG_DELTA_R3" "MIG_DELTA_R4"
## [46] "MIG_EDMS" "MPCA_BOL" "MPCA_DAL"
## [49] "MPCA_REPORT" "NAGIOS_ADMIN" "NCT"
## [52] "NIGHTLY" "NODE_FLOW" "NODE_FLOW_LINK_USER"
## [55] "NODE_FLOW_USR" "ONBASE_LINK" "OPAL"
## [58] "PCASEND" "PEST" "PROJECT_TRACKING"
## [61] "PUBLIC" "RAPIDS" "RESTFUL_UTIL"
## [64] "RSP" "SA_DATA" "SDW_UTIL"
## [67] "SPATIAL_PROD" "SR_DELTA" "SUPERAPIDS"
## [70] "SW_DELTA" "SYS" "SYSTEM"
## [73] "TABLEAU" "TACS" "TANKS"
## [76] "TEMPO" "TEMPO_MIG" "TEMPO_MN_CORE_WU"
## [79] "TEMPO_MN_LB" "TEMPO_MN_QUEUE" "TEMPO_MN_RAPIDS"
## [82] "TEMPO_MN_UTIL" "TEMPOAP" "TEMPOBP"
## [85] "THE_CRANK" "TIM_UPD" "TOAD"
## [88] "WH_AQ_EDA" "WH_CSW" "WH_CSW_2"
## [91] "WH_GROUNDWATER" "WH_HAZARDOUS_WASTE" "WH_HAZARDOUS_WASTE_2"
## [94] "WH_ISW" "WH_ISW_2" "WH_ONBASE"
## [97] "WH_SSTS" "WH_SURFACEWATER" "WH_SURFACEWATER_2"
## [100] "WH_TANKS" "WH_TANKS_2" "WH_TEMPO"
## [103] "WH_WIMN_2" "WIMN" "WIX"
## [106] "WJPORTER" "WQ_ASSESS" "WQ_ASSESS_LINK_USER"
## [109] "WQ_BIO" "WQ_DELTA" "WQISTS"# View the tables inside the Warehouse TEMPO schema
tbl_list_wh <- sqlTables(deltaw, schema = "WH_TEMPO")
# View the tables inside the real TEMPO
tbl_list <- sqlTables(deltaw, schema = "TEMPO")
# Let's find the MN chickens!
# Get the first 10 results in "MV_FEEDLOT"
feedlots <- sqlQuery(deltaw, "SELECT * FROM WH_TEMPO.MV_FEEDLOT",
max = 10, # Row limit for data pull, start small
stringsAsFactors = F)| MASTER_AI_ID | INT_DOC_ID | MASTER_AI_NAME | AI_PROGRAM_LIST | FEEDLOT_STATUS | REG_ACTIVITY_ID |
|---|---|---|---|---|---|
| 970 | 0 | Sustane Compost Facility | FE | active | REG20100001 |
| 1025 | 0 | Luoma Egg Ranch Inc | CS, FE, HW, SA, UT | active | REG20110001 |
| 1701 | 0 | Blair West Site | EV, FE, WW | active | REG20150002 |
| 1915 | 0 | Heartland Hutterian Brethren/Heartland Colonies | FE, HW, RR, SW, WW | active | REG20140001 |
| 1923 | 0 | Feikema Farms Home | FE | active | REG20140001 |
| 1925 | 0 | Gabrielson Paul | FE | inactive | NA |
Now for some real TEMPO seriousness.
Get TEMPO Agency Interest names and IDs
fac_ids <- sqlFetch(deltaw, "TEMPO.AGENCY_INTEREST", max = 10000, stringsAsFactors = F)
glimpse(fac_ids)## Observations: 10,000
## Variables: 10
## $ MASTER_AI_ID <int> 4445, 4446, 4447, 4448, 4449, 4450, 4451, 4452,...
## $ INT_DOC_ID <int> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,...
## $ MASTER_AI_NAME <chr> "Parkview Estates (Lake Elmo)", "Kilkenny Pond"...
## $ AI_TYPE_CODE <chr> "CON", "CON", "CON", "CON", "CON", "CON", "CON"...
## $ START_DATE <dttm> 1999-02-22 00:00:00, 1999-02-22 00:00:00, 1999...
## $ END_DATE <dttm> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA...
## $ USER_LAST_UPDT <chr> "SYSTEM ", "SYSTEM ", "RGAGLE ", "RGAGLE ",...
## $ TMSP_LAST_UPDT <dttm> 2013-02-05 12:14:16, 2013-02-05 12:14:16, 2014...
## $ USER_CREATED <chr> "DELTA_M_R1", "DELTA_M_R1", "DELTA_M_R1", "DELT...
## $ TMSP_CREATED <dttm> 1999-02-22 08:33:28, 1999-02-22 08:38:25, 1999...Get facility locations
locations <- sqlFetch(deltaw, "TEMPO.SUBJ_ITEM_LOCATION", max = 10000, stringsAsFactors = F)| MASTER_AI_ID | INT_DOC_ID | SUBJECT_ITEM_CATEGORY_CODE | SUBJECT_ITEM_ID | SECTION_CODE | TOWNSHIP_CODE |
|---|---|---|---|---|---|
| 2503 | 0 | AISI | 2503 | NA | NA |
| 2504 | 0 | AISI | 2504 | NA | NA |
| 2505 | 0 | AISI | 2505 | NA | NA |
| 2506 | 0 | AISI | 2506 | NA | NA |
| 2507 | 0 | AISI | 2507 | NA | NA |
| 4987 | 0 | AISI | 4987 | NA | NA |
left_join()
Go here for an introduction to left_join() using cats.
Now we’re ready to left_join() our two tables together.
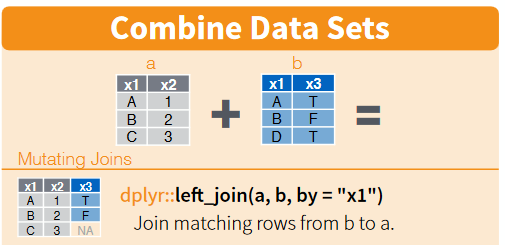
Using left_join(table_A, table_B) ensures that the result will contain all the rows and columns in table_A. The values in the columns of table_B will only be joined to table_A when they have a value in common. In the case below, location results will only be joined to the fac_ids table, when both tables contain a row of data with the same MASTER_AI_ID.
Join locations to facilities using the Master AI ID
fac_locs <- left_join(fac_ids, locations, by = "MASTER_AI_ID")
# Show lat/long for facilities
select(fac_locs, MASTER_AI_ID, MASTER_AI_NAME, X_COORD_VALUE , Y_COORD_VALUE) %>% head(7)## MASTER_AI_ID MASTER_AI_NAME X_COORD_VALUE
## 1 4445 Parkview Estates (Lake Elmo) <NA>
## 2 4446 Kilkenny Pond 484362.77456254
## 3 4447 Provence Creek 436710.48645318
## 4 4448 Phase 4 Lndfl Const & Access Rd 268891.80158881
## 5 4449 SP 42-606-08 285430.24316692
## 6 4450 SAP 42-607-13 280111.77972373
## 7 4451 Lyon County Ditch 62 Improv 280111.77972373
## Y_COORD_VALUE
## 1 <NA>
## 2 4950423.0653289
## 3 4965334.23034951
## 4 4914447.65435555
## 5 4921407.74623715
## 6 4925821.75474194
## 7 4925821.75474194Pop Quiz, hotshot!
According to TEMPO, which Municipality is the facilty ‘BrandFX LLC’ located in?
There is no BrandFX LLC facility.
Dunnell
St. Louis
Mahnomen
Walker
Show solution
Dunnell
You sure aren’t kitten around! Great work!
Water data
EQUIS | Water monitoring
# View the tables inside the EQUIS schema
equis_tbls <- sqlTables(deltaw, schema = "EQUIS")
equis_tbls %>% head(11)## TABLE_CAT TABLE_SCHEM TABLE_NAME TABLE_TYPE REMARKS
## 1 <NA> EQUIS ACCEPTABLE_USE TABLE <NA>
## 2 <NA> EQUIS AT_COMPANY TABLE <NA>
## 3 <NA> EQUIS AT_COMPANY_PERSON TABLE <NA>
## 4 <NA> EQUIS AT_DQM_RESULT TABLE <NA>
## 5 <NA> EQUIS AT_EQUIPMENT_PARAMETER TABLE <NA>
## 6 <NA> EQUIS AT_FACILITY TABLE <NA>
## 7 <NA> EQUIS AT_FILE_TYPE_PARAMETER TABLE <NA>
## 8 <NA> EQUIS AT_GEO_UNIT TABLE <NA>
## 9 <NA> EQUIS AT_SAMPLE_CHAIN_OF_CUSTODY TABLE <NA>
## 10 <NA> EQUIS AT_SAMPLE_SDG TABLE <NA>
## 11 <NA> EQUIS AT_SPM_COMMITMENT_PLANNED_TASK TABLE <NA>Pull EQUIS surface water data
library(ggplot2)
# Grab 5,000 rows from DT_WELL
eq_wells <- sqlQuery(deltaw, paste0("SELECT * FROM EQUIS.DT_WELL"),
max = 5000,
stringsAsFactors = F,
as.is = T)
# Histogram of well depths
eq_wells %>% ggplot(aes(x = as.numeric(DEPTH_OF_WELL))) + geom_histogram()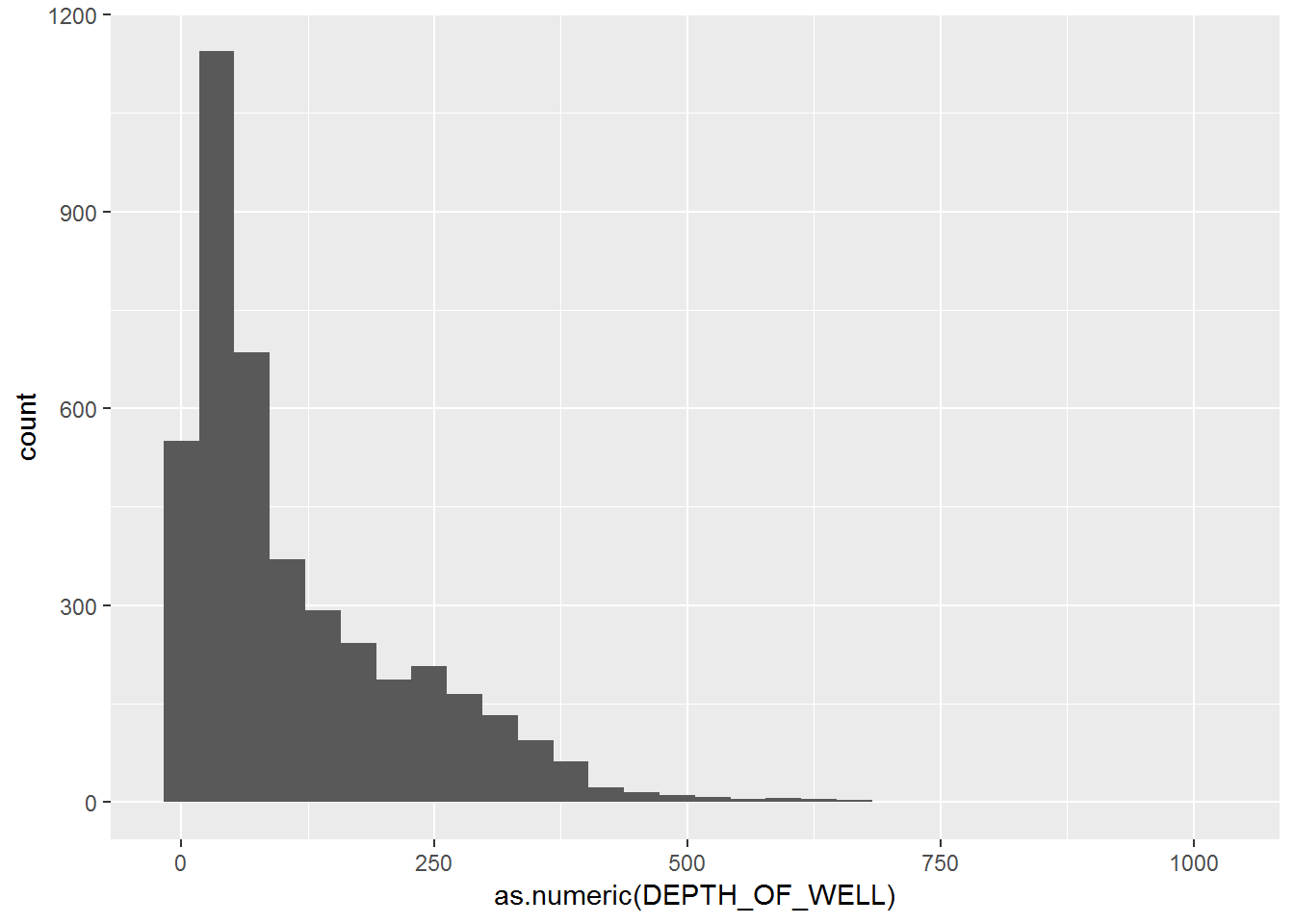
# Boxplot of depth by well purpose
eq_wells <- mutate(eq_wells,
DEPTH_OF_WELL = as.numeric(eq_wells$DEPTH_OF_WELL),
WELL_PURPOSE = as.factor(WELL_PURPOSE))
eq_wells %>%
ggplot(aes(x = WELL_PURPOSE, y = as.numeric(DEPTH_OF_WELL), fill = WELL_PURPOSE)) +
geom_boxplot() + scale_y_log10() +
theme_minimal()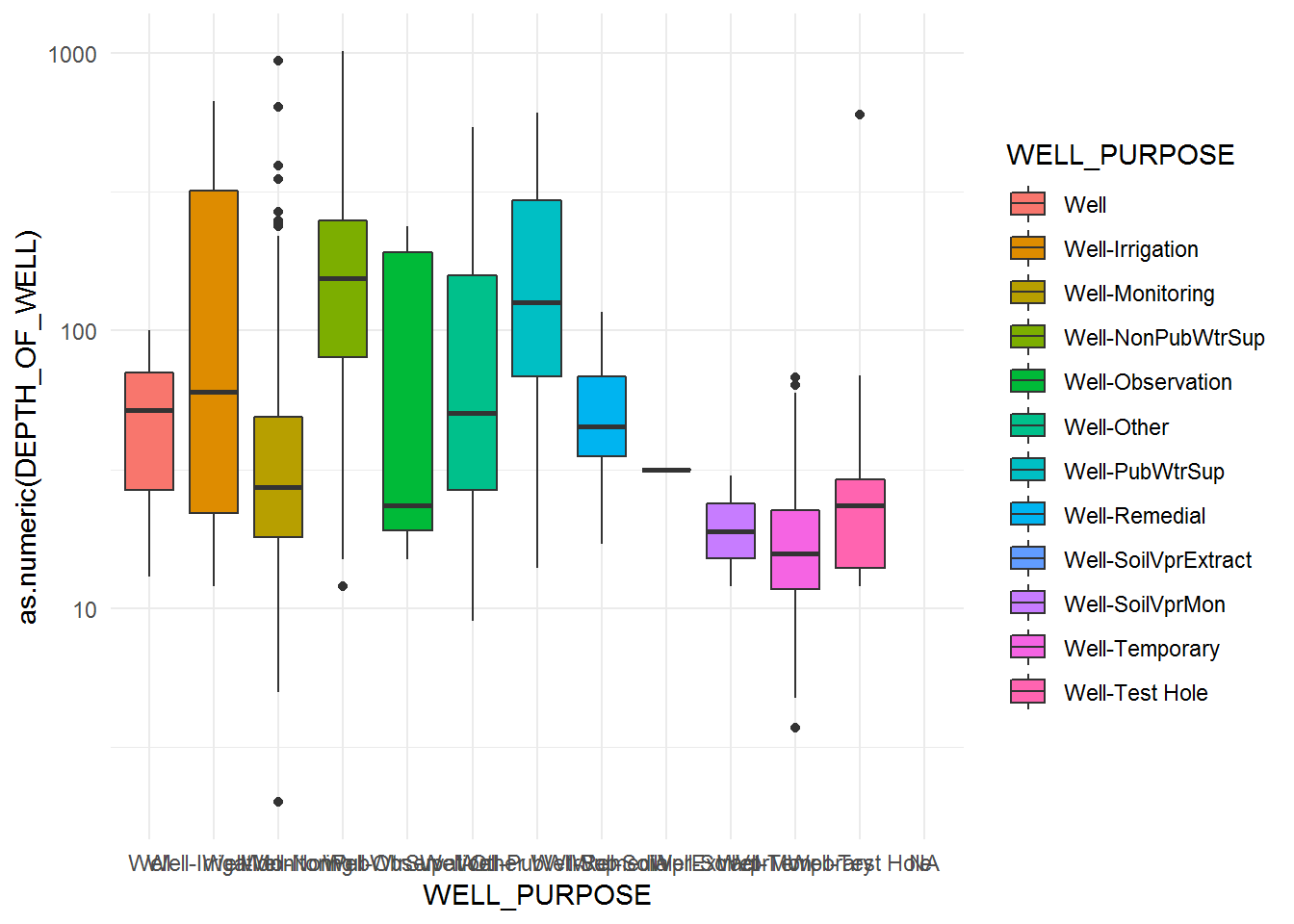
# Close all open connections
odbcCloseAll() You unlocked a shortcut!
You discovered an EQUIS CSV file.
Read in the water temperature data using read_csv().
library(readr)
## CSV file location
filepath <- "X:/Agency_Files/Outcomes/Risk_Eval_Air_Mod/_Air_Risk_Evaluation/R/R_Camp/Student Folder/Sample data/surface_water_temp_2015_16.csv"
# This file is BIG!
sw <- read_csv(filepath)
# Show top rows
head(sw[ , 1:5])## # A tibble: 6 x 5
## FACILITY_ID FACILITY_CODE SYS_LOC_CODE LOC_NAME SAMPLE_ID
## <int> <chr> <chr> <chr> <int>
## 1 1 MNPCA S005-170 <NA> 33429119
## 2 1 MNPCA S005-170 <NA> 33429120
## 3 1 MNPCA S005-170 <NA> 33429121
## 4 1 MNPCA 38-0637-00-203 Bald Eagle 37064183
## 5 1 MNPCA 38-0637-00-203 Bald Eagle 37064184
## 6 1 MNPCA 38-0637-00-203 Bald Eagle 37064185You will see a few issues with this data.
- There are location names missing.
- There are results flagged as not detected.
- There are a lot of excess columns we don’t need.
Let’s use our favorite dplyr functions to clean it up.
library(dplyr)
# Take a quick look
glimpse(sw)
# Get rid of missing locations
sw <- filter(sw, !is.na(LOC_NAME))
# Keep only the detected values
## Warning: This usually isn't a great idea, but we're in a hurry.
## Good practice would be to review missing values, and generate summaries that incorporate non-detect values.
sw <- filter(sw, DETECT_FLAG == "Y")
# Keep only *useful* columns
sw <- select(sw, LOC_NAME, SAMPLE_DATE, CHEMICAL_NAME, REPORT_RESULT_VALUE, REPORT_RESULT_UNIT)Let’s compare temperature to dissolved oxygen
All of the temperature and dissolved oxygen results are in the same column with the chemical name in a separate column. What if we want the dissolved oxygen and temparture results in separate columns?
We can use the spread() function from the tidyr package to do this. Let’s install it!

install.packages("tidyr")
library(tidyr)
sw_wide <- spread(sw, CHEMICAL_NAME, REPORT_RESULT_VALUE)
# Error!!! See below to resolve.We’re getting an error because we have multiple observations (duplicates) for the exact same sampling time. Let’s average the results taken at the same place and time.
# Group by site, date, and chemical; and then average the observation
sw <- sw %>%
group_by(LOC_NAME, SAMPLE_DATE, CHEMICAL_NAME, REPORT_RESULT_UNIT) %>%
summarize(REPORT_RESULT_VALUE = mean(REPORT_RESULT_VALUE, na.rm = T)) %>%
ungroup()
# Now let's try splitting the observation into 2 columns again.
sw_wide <- spread(sw, CHEMICAL_NAME, REPORT_RESULT_VALUE)
# Show table
head(sw_wide)## # A tibble: 6 x 5
## LOC_NAME SAMPLE_DATE REPORT_RESULT_U~ `Dissolved oxyg~ `Temperature, w~
## <chr> <chr> <chr> <dbl> <dbl>
## 1 14MN060 7/21/2016 1~ deg C NA 23.9
## 2 14MN060 7/21/2016 1~ mg/L 7.1 NA
## 3 14MN060 8/3/2016 10~ deg C NA 25.4
## 4 14MN060 8/3/2016 10~ mg/L 7.27 NA
## 5 14MN080 6/30/2016 1~ deg C NA 19.1
## 6 14MN080 6/30/2016 1~ mg/L 8.48 NAThis looks great, Temp and DO are in separate columns, but something doesn’t look right. The unit column is creating different rows for temp and DO, so let’s remove the units column for now.
# Drop units column
sw <- select(sw, -REPORT_RESULT_UNIT)
# Try the 3rd time, it'll be charmed
sw_wide <- spread(sw, CHEMICAL_NAME, REPORT_RESULT_VALUE)
head(sw_wide)## # A tibble: 6 x 4
## LOC_NAME SAMPLE_DATE `Dissolved oxygen (DO~ `Temperature, wate~
## <chr> <chr> <dbl> <dbl>
## 1 14MN060 7/21/2016 11:30:00 ~ 7.1 23.9
## 2 14MN060 8/3/2016 10:50:00 AM 7.27 25.4
## 3 14MN080 6/30/2016 1:50:00 PM 8.48 19.1
## 4 14MN081 3/2/2016 2:00:00 PM 13.7 0.6
## 5 14MN081 6/30/2016 2:10:00 PM 6.19 21.0
## 6 Acorn 5/12/2016 12:00:00 ~ 9.81 13.0Things look good now, but the DO and temp column names have spaces in them. We can technically leave them this way, but they can create trouble for us later on. Let’s use names() to tidy them.
# Assign the table names as a list
names(sw_wide) <- c("location", "sample_date", "DO_mg_per_L", "temp_C")Now back to KILLER bacteria

The deadly Caninus-morbidium (CM) is believed to be headed your way. We’ve found that it likes warm water and low oxygen, but it really dislikes fish and fast moving water.
According to our measurements we’ve seen them living in temperatures greater than 23 C, but less than 28 C. The dissolved oxygen range has been greater than 4, but less than 6.
Which water bodies would be hospitable to this bacteria?
Use filter() to find the water bodies that might be home to deadly CM.
bad_water <- filter(sw_wide)Fast water
The function grepl() can be used to find the water bodies with “River” in their name.
bad_water$location
bad_water <- filter(bad_water, !grepl("River", location))
# Use tolower() to account for capitalization issues
bad_water <- filter(bad_water, !grepl("river", tolower(location)))Now let’s plot the data for one of these water bodies over time.
Maybe we can find some clues that point to a water body becoming infected with CM.
# This one is the best ditch
favorite_wb <- "Judicial Ditch 2"
sw_fav <- filter(sw_wide, location == favorite_wb)ggplot(sw_fav, aes(x = sample_date, y = DO_mg_per_L)) +
geom_line() +
scale_x_datetime()
# ERROR! Nooo!!! See below to resolve.Uh oh, this doesn’t work because our dates are character objects and are not date/time objects. What should we do now?
- Give up. (Return to top of page.)
- Just keep trying the same script over and over again until it works. (Return to beginning of this sentence and read again.)
- Scroll down to find a package that will change columns into datetime objects. (Continue below.)
Good choice!
Let’s install lubridate to fix our date problems.

install.packages("lubridate")
library(lubridate)
# Convert sample_date to date object (something R knows is a date)
sw_fav <- mutate(sw_fav, sample_date = mdy_hms(sample_date))
# Try the plots again
# DO over time
ggplot(sw_fav, aes(x = sample_date, y = DO_mg_per_L)) +
geom_line() +
scale_x_datetime() +
labs(title = "DO over time at JD2",
subtitle = "Yes, Judicial Ditch 2 is important",
x = "Date of sample",
y = "Dissolved oxygen (mg/L)")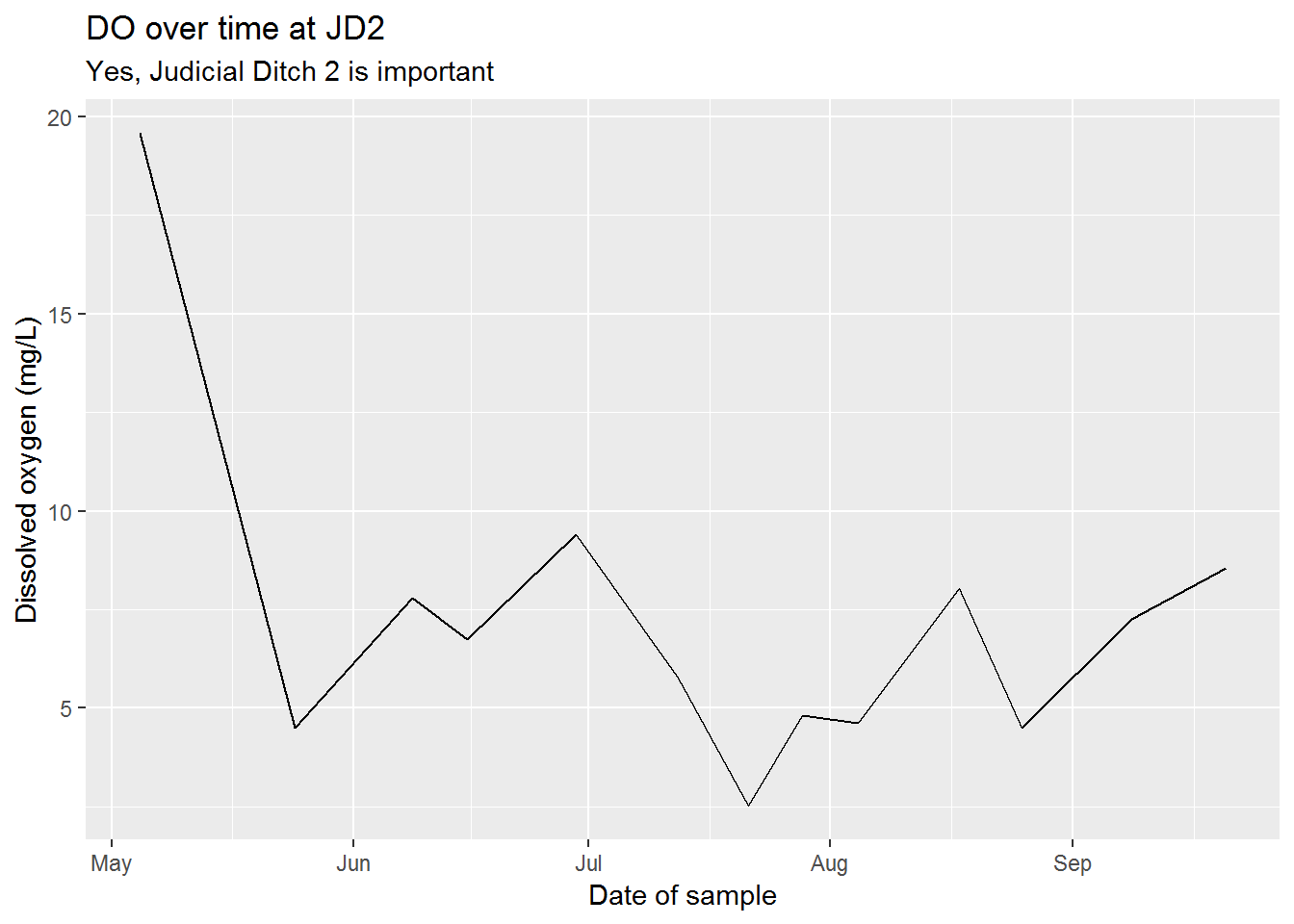
# Temperature over time
ggplot(sw_fav, aes(x = sample_date, y = temp_C)) +
geom_line() +
scale_x_datetime() +
labs(title = "Temp over time at JD2",
subtitle = "Judicial Ditch 2 is still important",
x = "Date of sample",
y = "Temp (in Celsius because Fahrenheit is stupid)")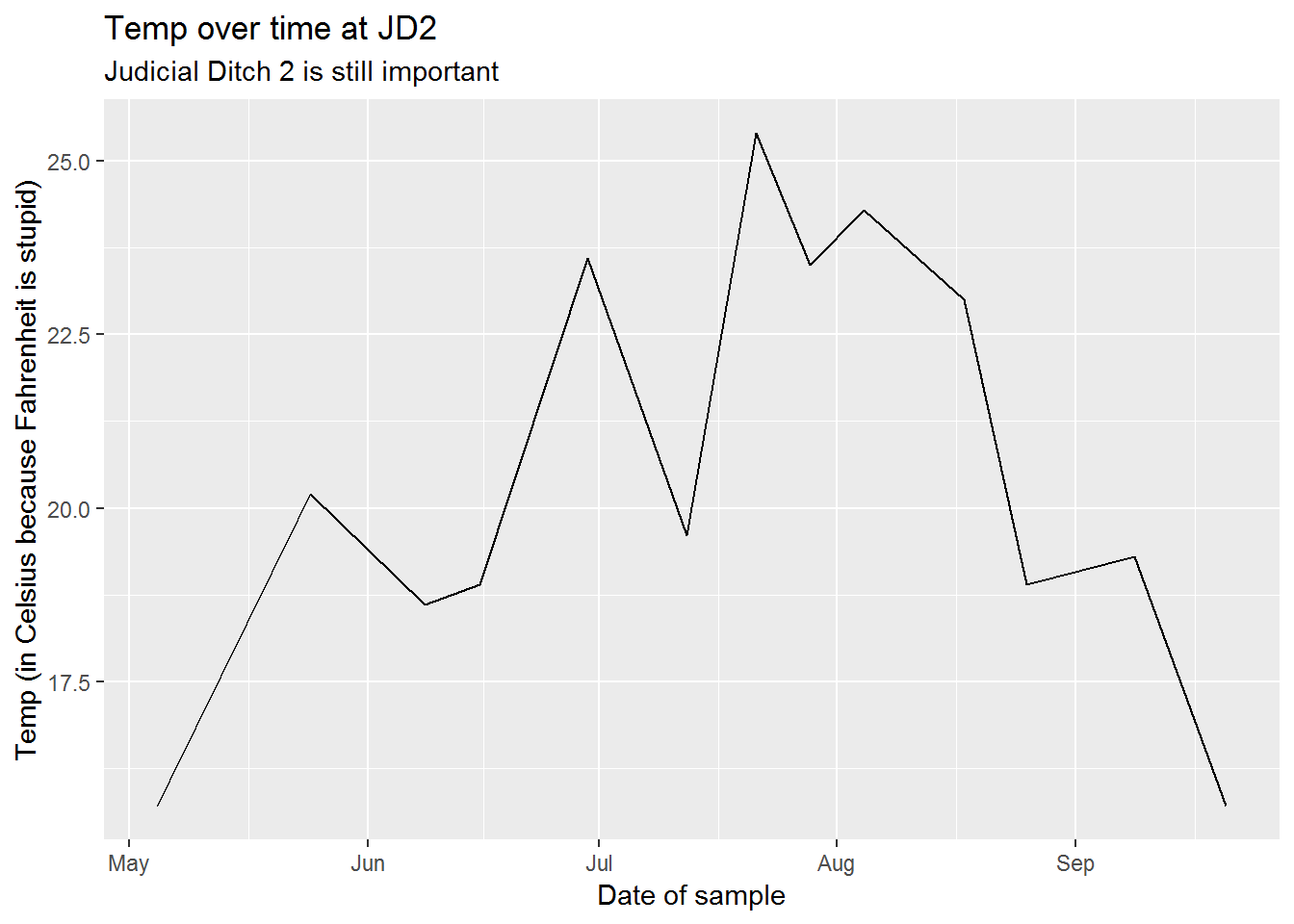
# Temperature vs DO correlation
ggplot(sw_fav, aes(x = temp_C, y = DO_mg_per_L)) +
geom_point() +
labs(title = "Temp vs. DO at JD2",
subtitle = "What is the relationship between temp and DO?",
x = "Temp (in Celsius because Fahrenheit is so you know)",
y = "Dissolved oxygen (mg/L)")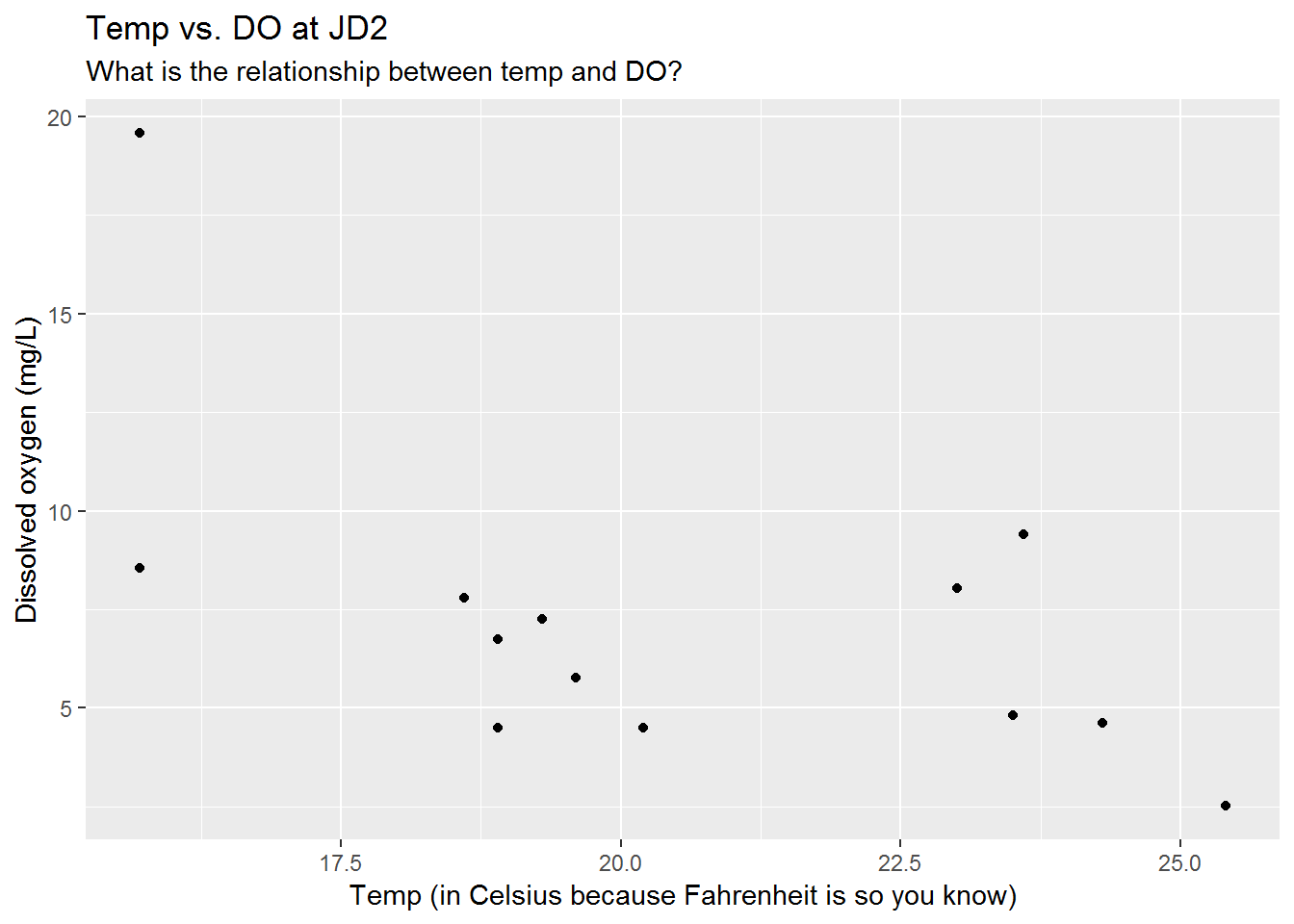
Air data
CEDR / Rapids | Air emissions inventory
CEDR is the one and only central air emissions data repository. It stores air emission data about all kinds of sources in Minnesota.
library(RODBC)
# Connect to Delta
deltaw <- odbcConnect("deltaw",
uid = user,
pwd = password,
believeNRows = FALSE)
# Show all tables in RAPIDS schema
rapids_tbls <- sqlTables(deltaw, tableType = "TABLE", schema = "RAPIDS")
# Get inventory year code
inv_codes <- sqlQuery(deltaw, "SELECT * FROM RAPIDS.INV_INVENTORIES",
max = 100,
stringsAsFactors = F)
# Get code for 2014
inv_id <- filter(inv_codes, INVENTORY_YEAR == 2014)$RID
# Get emissions for inventory year
emissions <- sqlQuery(deltaw, paste0("SELECT * FROM RAPIDS.INV_PROCESS_EMISSIONS WHERE INVENTORY_RID = ", inv_id),
max = 10000,
stringsAsFactors = F,
as.is = T)
# Additional SQL query options for emissions
##" AND MATERIAL_CODE = 'CO2'",
##" AND PROCESS_RID = '101276120'"),
# Get emission units
e_units <- sqlQuery(deltaw, paste0("SELECT * FROM RAPIDS.INV_EMISSION_UNITS WHERE INVENTORY_RID = ", inv_id),
max = 10000,
stringsAsFactors = F,
as.is = T)
# Get emission processes
e_process <- sqlQuery(deltaw, paste0("SELECT * FROM RAPIDS.INV_PROCESSeS WHERE INVENTORY_RID = ", inv_id),
max = 10000,
stringsAsFactors = F,
as.is = T)
# Get SCC reference code description
scc <- sqlQuery(deltaw, paste0("SELECT * FROM RAPIDS.REF_SCC_CODES"),
stringsAsFactors = F,
as.is = T)
# Join SCC code EI sector to source params
e_process <- left_join(e_process, select(scc, SCC_CODE, EI_SECTOR))
# Convert SCC code to type character with as.character()
e_process <- mutate(e_process, SCC_CODE = as.character(SCC_CODE))
# Try to join again
e_process <- left_join(e_process, select(scc, SCC_CODE, EI_SECTOR))
# Check if EI_SECTOR column added to end of table
glimpse(e_process)## Observations: 10,000
## Variables: 33
## $ RID <chr> "101131651", "101131653", "101131...
## $ INVENTORY_RID <chr> "101123730", "101123730", "101123...
## $ SOURCE_RID <chr> "101131475", "101131475", "101131...
## $ EMISSION_UNIT_RID <chr> "101131650", "101131652", "101131...
## $ PROCESS_ID <chr> "EU046PD001", "EU047PD001", "EU04...
## $ SCC_CODE <chr> "10200603", "20200102", "20200102...
## $ CONFIDENTIAL_FLAG <chr> "N", "N", "N", "N", "N", "N", "N"...
## $ SHORT_DESC <chr> "Natural gas", "Diesel", "Diesel"...
## $ AIRCRAFT_ENGINE_TYPE_CODE <chr> NA, NA, NA, NA, NA, NA, NA, NA, N...
## $ EMISSION_TYPE_CODE <chr> NA, NA, NA, NA, NA, NA, NA, NA, N...
## $ CONTROL_APPROACH_RID <chr> NA, NA, NA, NA, NA, "101131517", ...
## $ BEGIN_OPERATION_DATE <chr> NA, NA, NA, NA, NA, NA, NA, NA, N...
## $ END_OPERATION_DATE <chr> NA, NA, NA, NA, NA, NA, NA, NA, N...
## $ EIS_PROGRAM_SYSTEM_CODE <chr> NA, NA, NA, NA, NA, NA, NA, NA, N...
## $ ID_EFFECTIVE_DATE <chr> NA, NA, NA, NA, NA, NA, NA, NA, N...
## $ ID_END_DATE <chr> NA, NA, NA, NA, NA, NA, NA, NA, N...
## $ PROCESS_EIS_ID <chr> NA, NA, NA, NA, NA, NA, NA, NA, N...
## $ MACT_CODE <chr> NA, NA, NA, NA, NA, NA, NA, NA, N...
## $ MACT_COMPLIANCE_STATUS <chr> NA, NA, NA, NA, NA, NA, NA, NA, N...
## $ WINTER_ACTIVITY_PCT <chr> "25", "25", "25", "25", "25", "25...
## $ SPRING_ACTIVITY_PCT <chr> "25", "25", "25", "25", "25", "25...
## $ SUMMER_ACTIVITY_PCT <chr> "25", "25", "25", "25", "25", "25...
## $ FALL_ACTIVITY_PCT <chr> "25", "25", "25", "25", "25", "25...
## $ ACTUAL_HOURS_PER_YEAR <chr> "43", "44", "44", "50", "50", "86...
## $ ACTUAL_WEEKS_PER_YEAR <chr> "52", NA, NA, NA, NA, NA, NA, NA,...
## $ ANNUAL_AVERAGE_HOURS_PER_DAY <chr> "24", "1", "1", "1", "1", "24", "...
## $ ANNUAL_AVERAGE_DAYS_PER_WEEK <chr> "7", "1", "1", "1", "1", "7", "1"...
## $ UPDATE_TIME <chr> "2015-04-01 16:44:14.000000", "20...
## $ UPDATE_USER <chr> "NETSVCU", "NETSVCU", "NETSVCU", ...
## $ CREATE_TIME <chr> "2014-12-08 09:00:13.000000", "20...
## $ CREATE_USER <chr> "CEDR", "CEDR", "CEDR", "CEDR", "...
## $ COMMENT_TEXT <chr> NA, NA, NA, NA, NA, NA, NA, NA, N...
## $ EI_SECTOR <chr> "Fuel Comb - Industrial Boilers, ...Microsoft Access
- Your Microsoft drivers are old and only work in old school “32-bit” mode.
- To switch to 32-bit hipster mode, go to Tools > Global Options…
- At the top next to “R version:”, select Change…
- Choose the 32-bit version of R and click OK.
- Close R by clicking the big red X, or pressing
CTRL + Q. - Reopen your project.
- Now we can tell R the path to the Access db and the table name or view that we want to import from Access.
- We pull in the movie data if it is not already in our environment.
- Then we
left_join()to the movie dataset to see which movies were released in the year of our births.
library(RODBC) # For Access
library(readxl) # For Excel
library(dplyr) # For left_join
library(stringr) # For cleaning text data with garbage and spaces
db_path <- "X:/Agency_Files/Outcomes/Risk_Eval_Air_Mod/_Air_Risk_Evaluation/R/R_Camp/Student Folder/Sample data/Varietal Data.accdb"
table_name <- "Academy_awards"
bigdb <- odbcConnectAccess2007(db_path)
academy_awards <- sqlFetch(bigdb, table_name,
rownames = F,
stringsAsFactors = F)
odbcClose(bigdb)
# Filter to only the best picture award category
academy_awards <- filter(academy_awards, Category == "Best Picture")
# Pull in movie data if it is not in your environment.
movies <- read_excel("X:/Agency_Files/Outcomes/Risk_Eval_Air_Mod/_Air_Risk_Evaluation/R/R_Camp/Student Folder/Sample data/IMDB movie data.xlsx", sheet = "use_this", skip = 2)
# Check movie titles
movies$movie_title %>% head()left_join()
Now we’re ready to left_join() our two tables together.
# Join the award nominations to the movies data table
awards_movies <- left_join(movies, academy_awards, by = c("movie_title" = "Nominee"))
# Select only rows that successfully joined and added a value to the Won? column
winning_movies <- filter(awards_movies, !is.na(`Won?`))Find the director with the most wins
library(ggplot2)
# group_by() director name to count the number of times their name appears
top_directors <- group_by(winning_movies, director_name) %>%
summarize(award_count = n()) %>%
arrange(desc(award_count))
# Column plot of top 12
ggplot(top_directors[1:10, ], aes(director_name, award_count)) + geom_col() + scale_color_brewer()When you’re done
- Switch your R version back to 64-bit in Tools > Global options.
- Close RStudio and re-open your project.
You’ve reached the end of this path. Return to the homepage and continue searching.